2017 年之前,大家运维管理管理体系的监控关键也是以 Zabbix 做为主要的解决方法。那时候数据库这一部分的监控服务项目也是采用的监控运维管理精英团队带来的服务项目。

照片来源于 Pexels
总的来说,Zabbix 的作用也是十分强有力的,并且应用也非常简单,大部分写写脚本制作就能完成特定运用的监控。
PS:现阶段早已并不是 Zabbix 了,运维管理精英团队根据 Open-Falcon 订制开发设计了一套统一的运维管理监控系统软件,自然这也是后话了。
我们在 2016 年就早已试着 MySQL 的容器化,2017 年逐渐大量运用。容器化之后 MySQL 总数急剧升高,根据平台化开展管理方法。
原先采用的 Zabbix 早已不能满足需求:
- 监控指标值过多,假如都连接到 Zabbix,网络服务器没法承担(那时候的服务器空间状况下)。
- 数据库运维平台对监控告警的管理方法必须连动解决。
- 数据库运维平台上实例删改时必须监控一键发觉实例。
- 有发展趋势预测分析、数据迅速统计分析的要求。
- 对监控指标值绘图有自定的要求。
因此大家 DB 精英团队内部结构想型号选择一款监控系统软件来支撑点以上要求。
技术选型
有关数据库的监控,大家并不愿资金投入过多人力资源去维护保养,终究监控系统软件并不是咱们的首要工作中。
因此必须选一款布署简易、服务器空间占有低、与此同时又能融合告警作用的监控系统软件。
尽管现阶段开源系统的监控系统软件或是有许多的,可是最后评定出来,或是挑选了更轻量的 Prometheus,可以迅速达到大家数据库监控的要求。
①便捷性
二进制文件运行、轻量 Server,有利于转移和维护保养、PromQL 测算函数公式丰富多彩,统计分析层面广。
②性能卓越
监控数据以时间段为层面统计分析状况较多,时钟频率数据库更适用监控数据的储存,按時间数据库索引特性更高一些,上百万监控指标值,每秒钟解决数十万的数据点。
③扩展性
Prometheus 适用联邦政府群集,可以让好几个 Prometheus 实例造成一个逻辑性群集,当单实例 Prometheus Server 解决的每日任务过多时,根据应用空间布局(Sharding) 联邦政府群集(Federation)可以对它进行拓展。
④易集成化
Prometheus 小区还带来了很多第三方完成的监控数据采集适用:JMX,EC2,MySQL,PostgresSQL,SNMP,Consul,Haproxy,Mesos,Bind,CouchDB,Django,Memcached,RabbitMQ,Redis,Rsyslog这些。
⑤数据可视化
内置了 Prometheus UI,根据这一 UI 可以同时对数据开展查看。融合 Grafana 可以灵便搭建精致细腻的监控数据图。
⑥强劲的汇聚英语的语法
内嵌数据库架构,可以根据 PromQL 的函数公式完成对数据的查看、汇聚。与此同时根据 PromQL 可以迅速订制告警标准。
实践活动
监控的目地
在做监控系统软件以前,最先我们要确立监控的目地。
在汇总相关内容的情况下,恰好在网络上看到了 CNCF 慈善基金会 Certified Kubernetes Administrator 郑云龙老先生根据《SRE:Google 运维解密》对监控目地的汇总,总结很及时,因此就直接引用过来了。
引入由来:
趋势性剖析:根据对监控样版数据的不断搜集和统计分析,对监控指标值开展趋势性剖析。
例如,根据对储存空间年增长率的分辨,我们可以提早预测分析在未来哪些时间阶段上必须对自然资源开展扩充。
告警:当系统软件发生或是将要出现异常时,监控系统软件必须迅速反应并通告管理人员,进而可以对问题开展更快的解决或是提早避免问题的产生,防止出现对项目的危害。
常见故障剖析与精准定位:当问题出现后,必须对问题开展调研和解决。根据对不一样监控监控及其历史时间数据的剖析,可以寻找并处理根本原因问题。
数据数据可视化:根据数据可视化车内仪表盘可以立即获得操作系统的运转情况、資源应用状况、及其服务项目运作情况等形象化的信息内容。
一个监控系统软件达到了以上的这种点,涉及到采集、剖析、告警、图型展现,健全遮盖了监控系统软件应当具有的作用。下边就解读我们都是怎样根据 Prometheus 来打造出数据库监控系统软件的。
大家的监控系统架构图介绍
我们在 2016 年末逐渐应用到现在,正中间也经历过几回构架演变。可是充分考虑阅读文章感受,被代替的方法就没有在这详说了,大家主要讲一下现阶段的软件架构设计和运用状况。
最先看一下整体的构架:
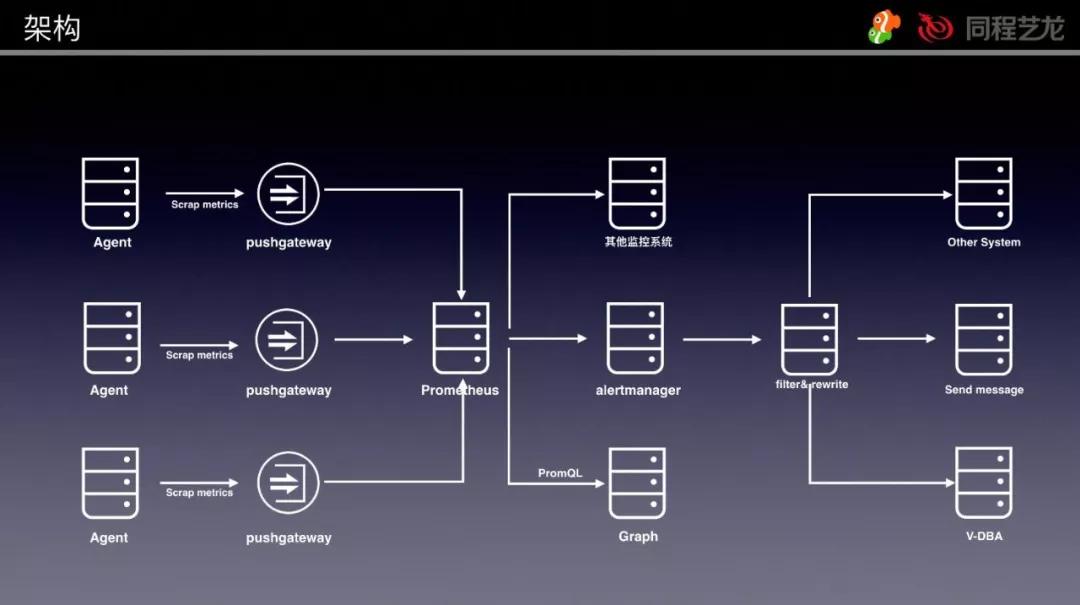
大家逐一介绍一下上边架构图中的內容:
①Agent
这也是大家用 Golang 开发设计的监控信息内容采集 Agent,承担采集监控指标值和实例日志。
监控指标主要包括了该宿主机的有关信息(实例、器皿)。由于我们都是容器化布署,单机版实例总数大约在 4-20 上下。
伴随着运维平台的实例删改,该宿主机上的实例信息内容有可能会产生变化。因此大家必须 Agent 可以觉察到这一转变,进而决策采集什么信息内容。
此外采集时间间隔保证了 10s,监控颗粒度可以做的更细,避免遗漏掉突发的监控指标值颤动。
②Pushgateway
这也是大家用的官网给予的部件,由于 Prometheus 是根据 Pull 的形式获得数据的。
假如让 Prometheus Server 去每一个连接点拉数据,那麼监控服务项目的负担便会非常大。
我们都是在监控好几千个实例的情形下保证 10s 的采集间距(自然选用联邦政府群集的方式还可以,可是那样就必须布署 Prometheus Server。再再加上告警有关的物品之后,全部构架能变的比较复杂)。
因此 Agent 采用数据消息推送至 pushgateway,随后由 Prometheus Server 去 pushgateway 上边 Pull 数据。
那样在 Prometheus Server 载入特性达到的情形下,每台设备就可以承重全部体系的监控数据。
充分考虑跨计算机房采集监控数据的问题,我们可以在每一个计算机房都布署 pushgateway 连接点,与此同时还能减轻单独 pushgateway 的工作压力。
③Prometheus Server
将 Prometheus Server 去 pushgateway 上边拉数据的间隔时间设定为 10s。好几个 pushgateway 的情形下,就配备好几个组就可以。
为了更好地保证 Prometheus Server 的高可用性,可以再加一个 Prometheus Server 放进外地容灾计算机房,配备和前边的 Prometheus Server 一样。
假如监控必须保存期长得话,还可以配备一个采集时间间隔比较大的 Prometheus Server,例如 5 分鐘一次,数据保存 1 年。
④Alertmanager
应用 Alertmanager 前,必须先在 Prometheus Server 上边界定好告警标准。大家的监控系统软件由于是给 DBA 用,因此告警指标值种类可以统一管理方法。
可是也有不一样群集或是实例界定的告警阀值是不一样的,这儿如何完成灵便配备,我后边再讲。
为了更好地处理 Alertmanager 点射的问题(高可用性见下面的图),我们可以配备成 3 个点,Alertmanager 引进了 Gossip 体制。
Gossip 体制为好几个 Alertmanager 中间带来了信息传递的体制。保证立即在好几个 Alertmanager 各自接受到同样告警信息内容的情形下,也只有一个告警通告被发给 Receiver。
Alertmanager 适用好几个种类的配备。自定模版,例如推送 HTML 的电子邮件;告警路由器,依据标识配对明确如何处理告警;接受人,适用电子邮件、手机微信、Webhook 多种不同告警;inhibit_rules,根据充分利用,可以降低废弃物告警的造成(例如设备服务器宕机,该设备上边全部实例的告警信息内容就可以忽视掉,避免告警飓风)。
大家告警是根据 Webhook 的方法,将开启的告警消息推送至特定 API,随后根据这一插口的业务开展二次生产加工。
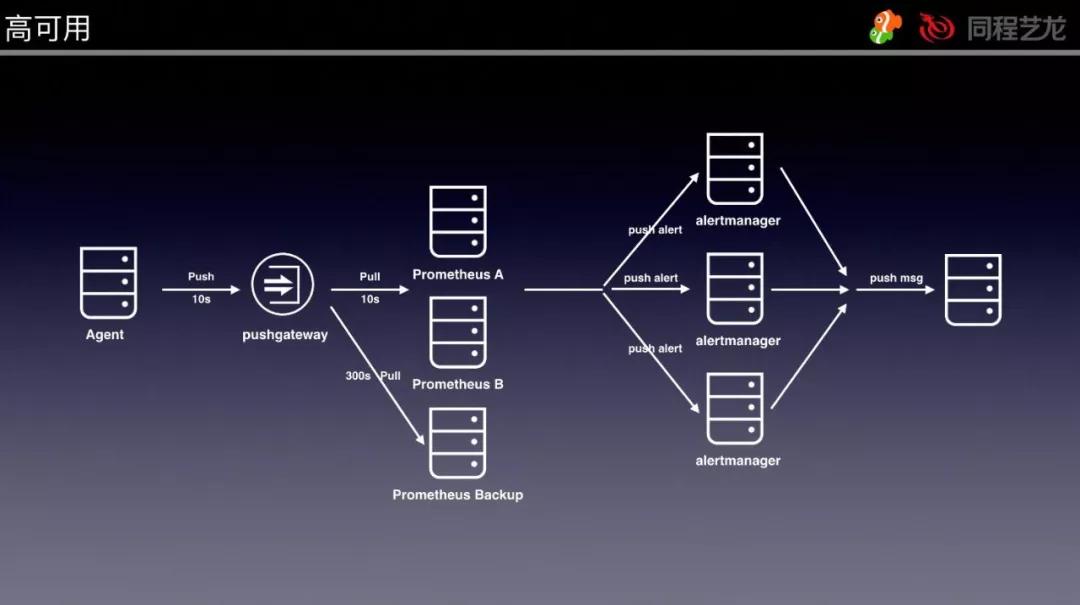
Prometheus 和 Alertmanager 的高可用性
⑤Filter&Rewrite控制模块
这一控制模块的功用便是完成 MySQL 群集告警标准过虑作用和告警內容改变。
先说一下告警标准过虑,由于上边提及是统一设定了告警标准,那麼如果有 DBA 必须对某些群集的告警阀值调节得话便会很不便,为了更好地彻底解决这个问题,我们在 Alertmanager 后边干了 Filter 控制模块。
这一控制模块传输到告警內容后,会分辨这条告警信息内容是不是超出 DBA 对于群集或是实例(实例优先高过群集)设定阀值范畴,假如超出就开启推送姿势。
告警推送依照级别不一样,推送方法不一样。例如大家界定了三个级别,P0、P1、P2,先后由高到低:
- P0,一切時间都是会开启,而且与此同时开启电話和手机微信告警。
- P1,8:00-23:00 只发微信告警,别的時间开启持续三次才开启推送。
- P2,8:00-23:00 发送手机微信告警,别的時间开启不推送。
下面的图是集群和实例的告警阀值管理页面(这也是集成化在数据库查询运维平台内部结构的一个作用),对于每一个集群和实例可以单独管理方法,新创建集群的过程中会依据选定 CPU 运行内存配备,默认设置得出一组与配备相匹配的告警阀值。
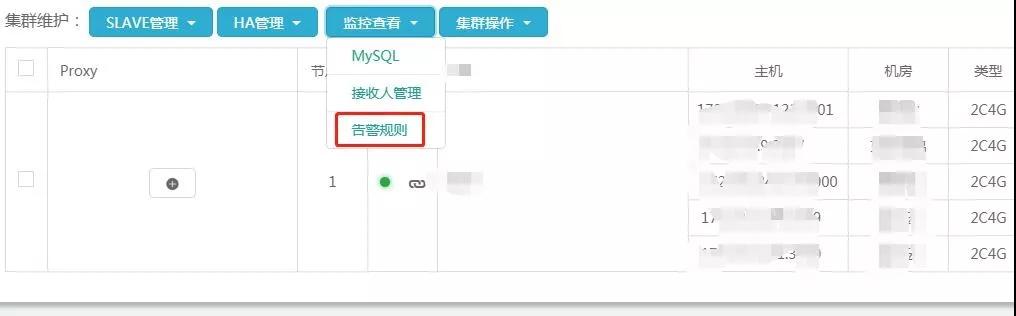
集群告警标准管理方法通道
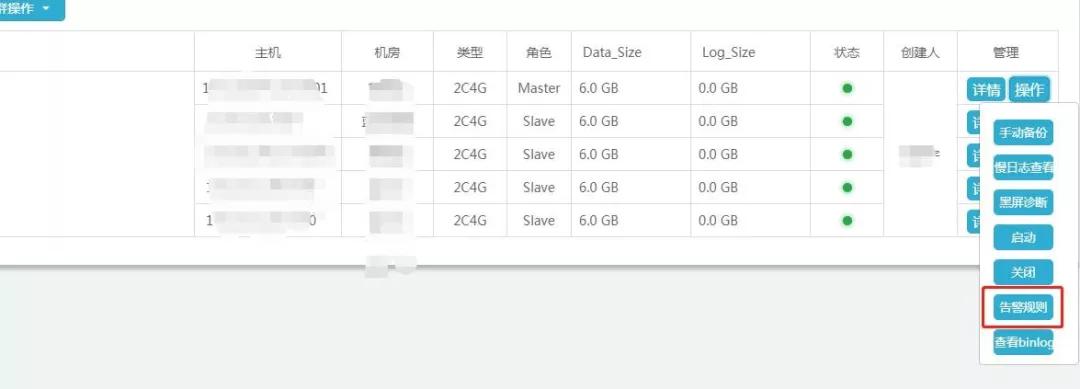
实例告警标准管理方法通道

告警标准管理方法
然后看一下告警內容 Rewrite,例如图中见到的附加接受人,除开 DBA 有一些开发设计同学们也想接受告警。
可是假如给他发一个 Thread_running 超过是多少的告警,她们很有可能搞不懂代表什么意思,或是什么情况会发生这一告警,必须关心哪些。
全部大家必须做一下告警內容的重新写过,让开发设计也可以看的搞清楚。下面的图便是大家改变之后的內容。
告警内容 Rewrite
也有告警关系,例如某一宿主机的硬盘 IO 高了,可是很有可能必须精准定位是哪个实例造成的,那麼大家就可以利用这一告警,随后去监控系统里边剖析很有可能造成 IO 高的实例,而且管理方法警报。
如下图所示:
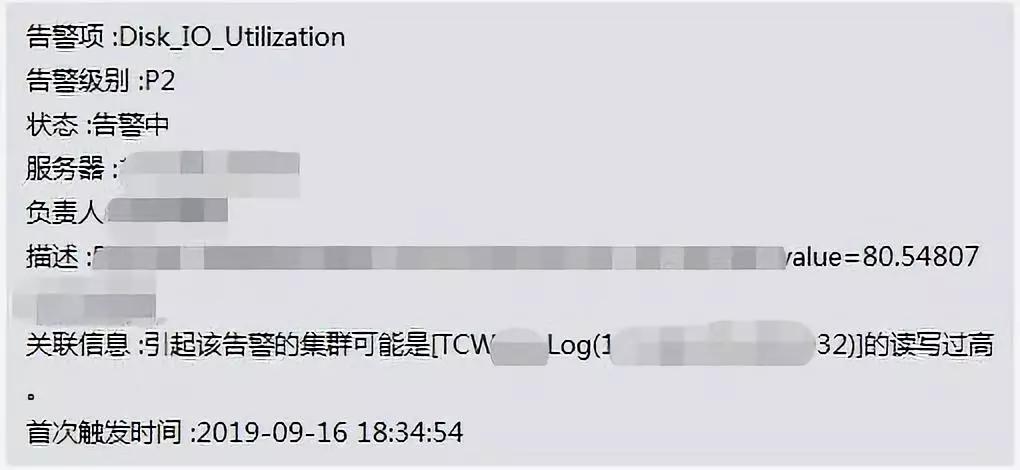
IO 告警关系实例信息内容
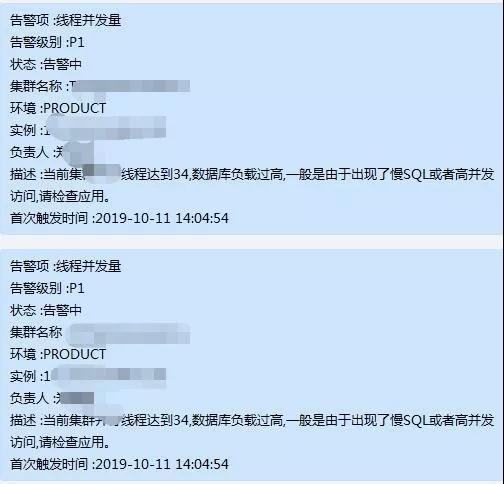
最终说一下告警收敛性,例如宿主机服务器宕机,那麼这一宿主机上边的 MySQL 实例都是会开启服务器宕机告警(MySQL 实例持续三个指标值汇报周期时间沒有数据信息,则判断会为实例出现异常),很多的告警会吞没掉关键告警,因此必须做一下告警收敛性。
我们都是那样做的,服务器宕机后由宿主机的告警信息内容来弄出实例的有关信息,一条告警就能看见全部信息内容,那样就能根据一条告警信息内容的內容,获知什么集群的实例受影响。
如下图所示:
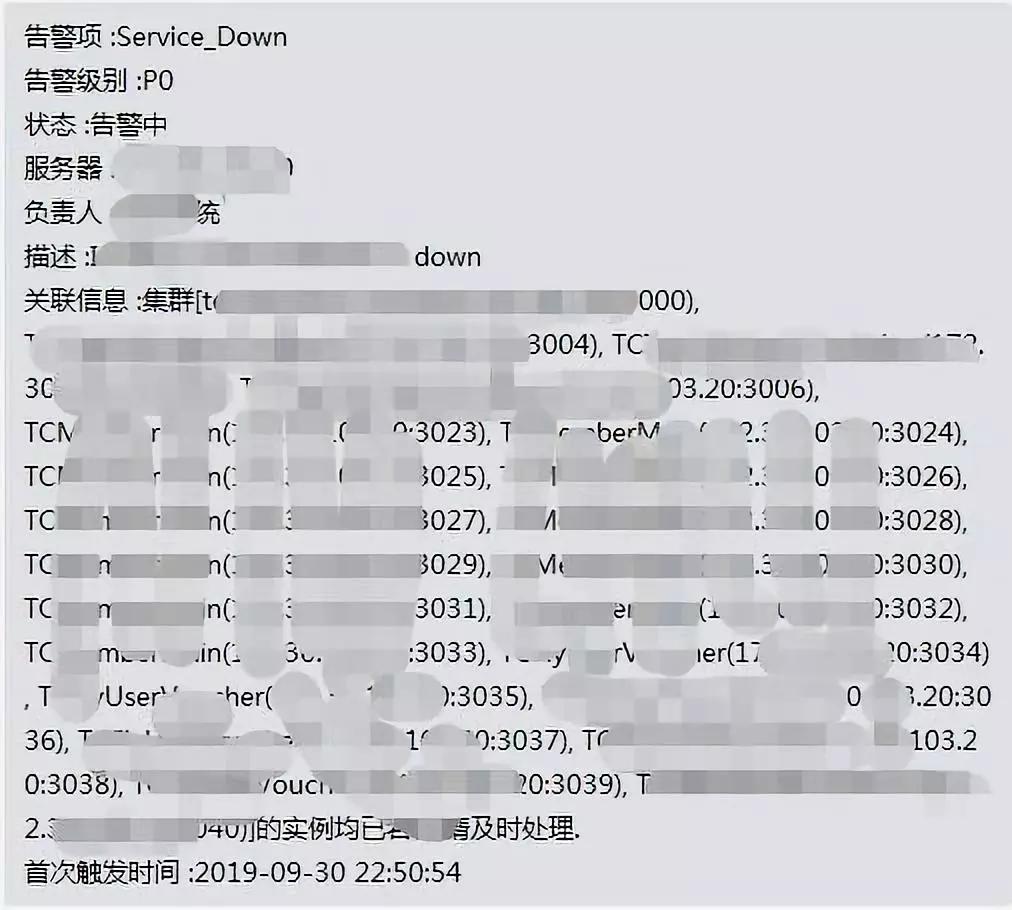
宿主机服务器宕机关系实例
⑥Graph(绘图)
Prometheus 极致适用 Grafana,我们可以根据 PromQL 英语的语法融合 Grafana,迅速完成监管图的展现。
为了更好地和运维平台关系,根据 URL 传参的方法,完成了运维平台立即开启特定集群和指定实例的监管图。
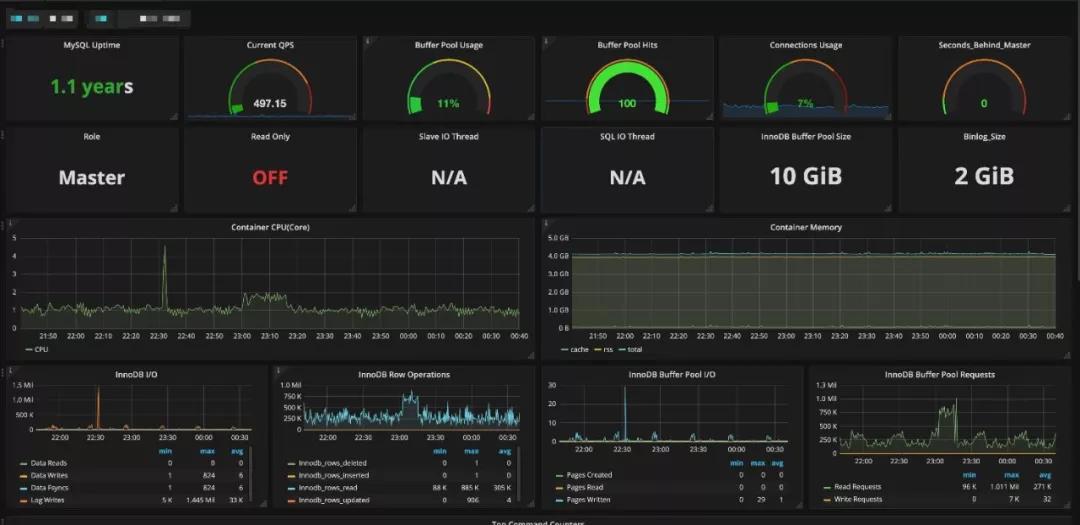
实例监控图
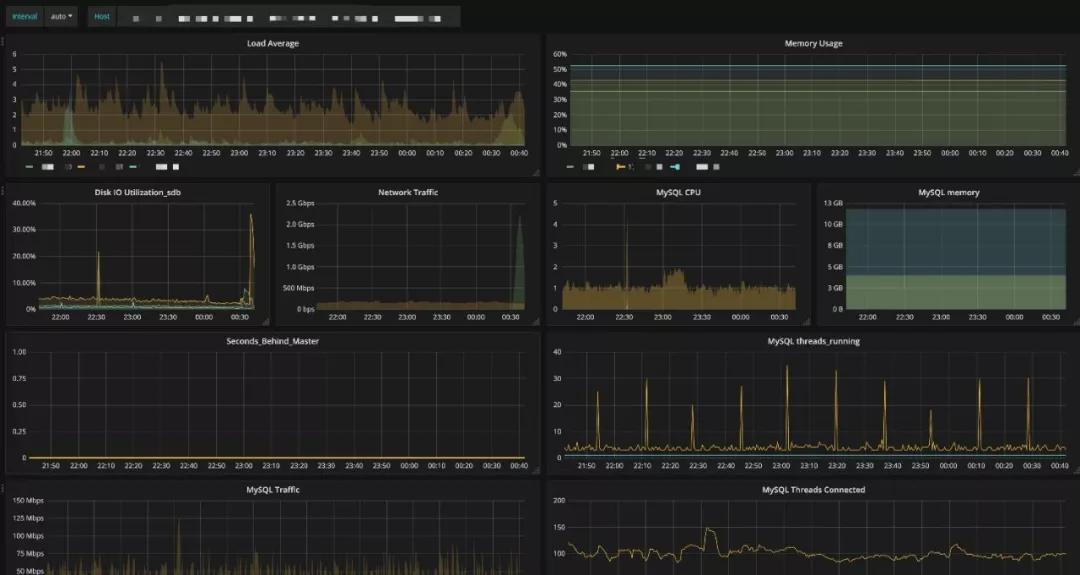
集群监管图
⑦V-DBA
这是一个 DBA 的智能化程序流程,可以依靠告警信息内容完成一些特定实际操作,这儿举一个过电压保护的事例,大家的过电压保护并不是一直打开的,仅有当开启了 thread_running 告警之后才会关系过电压保护的姿势。
实际计划方案见下面的图:
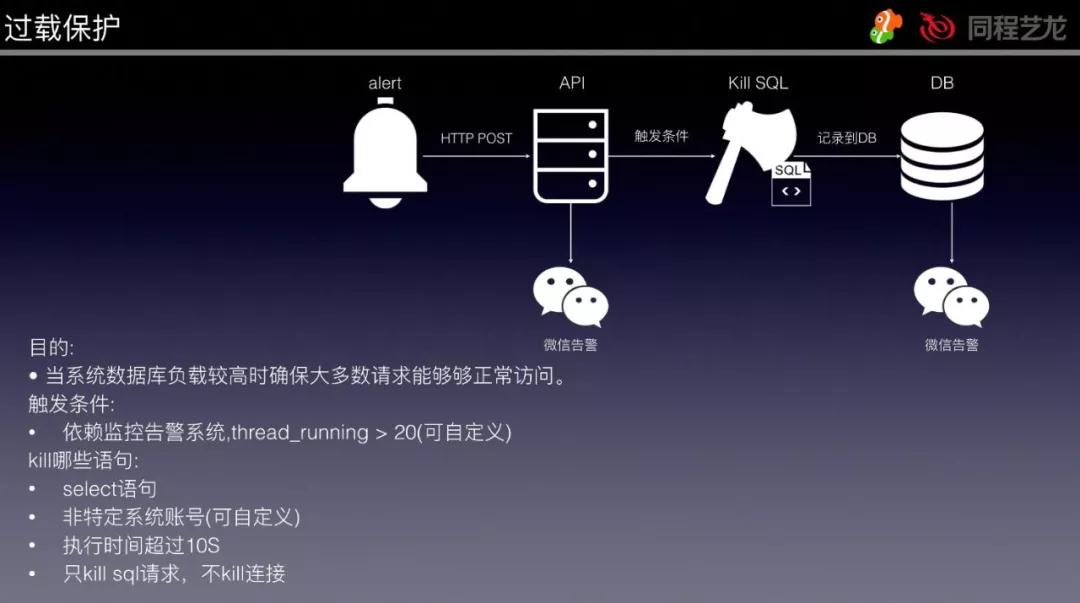
⑧告警管理方法
在运维平台上,大家有专业的网页页面用以管理方法告警,在移动端也做了兼容,便捷 DBA 随时随地都能联接到服务平台查询解决告警。
从下面中能够看见现阶段开启的告警目录,无色调标明的标志该告警早已被回应(归属于可维护性告警,回应之后不推送),有色彩的这一意味着未被回应告警(图上的这种归属于 P2 级别告警)。
此外可以注意到,这儿的告警內容由于是给 DBA 看,因此没做改变。

PC 端
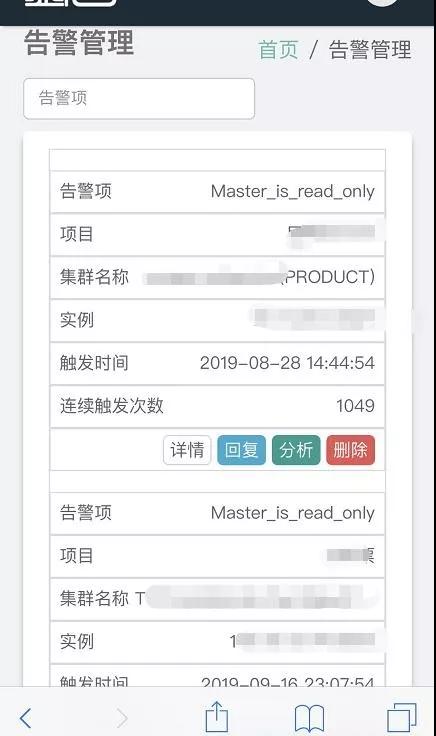
移动端
根据告警日志,大家融合 ES 和 Kibana 完成了告警数据统计分析的作用,这类互动的数据统计分析展现,可以协助 DBA 轻轻松松进行规模性数据库查询运维管理下的日常安全巡检,迅速精准定位有什么问题的集群并立即提升。

告警剖析
根据 Prometheus 的别的实践活动
根据 Prometheus 的计划方案,大家还做了别的监管告警有关作用拓展。
①集群得分
因为大家做了告警等级分类,绝大多数的告警全是 P2 级别,也就是大白天推送,为此来减少晚间的告警总数。
可是这样一来很有可能会错失一些告警,造成问题无法立即曝露,因此就做了集群得分的作用来剖析集群身体状况。
而且对于一个月的得分做了发展趋势展现,便捷 DBA 可以迅速分辨该集群是不是必须提升。
如下图所示:
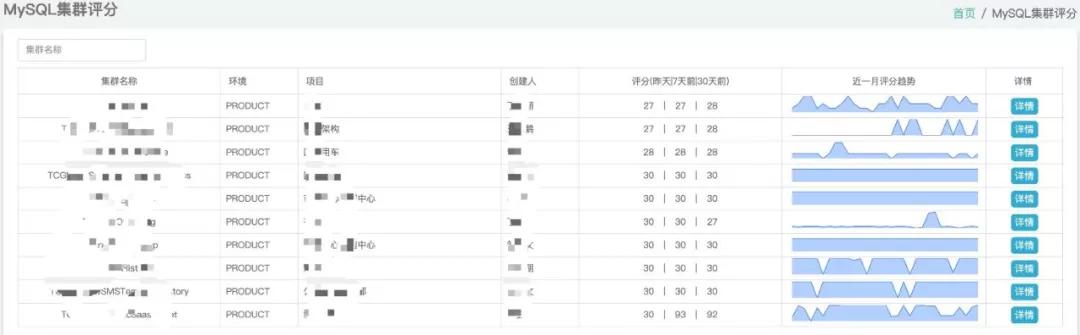
集群得分
点一下详细信息,可以进到该集群的宝贝详情面。可以查询 CPU、运行内存、硬盘的运用状况(这儿储存空间做到了 262%,意思是超出配额制了)。
此外也有 QPS、TPS、Thread_running 昨日和 7 日前的同期相比曲线图,用于观查集群要求量的转变状况。最下边的常见问题还会徽出罚分项是哪些,分别是什么实例。
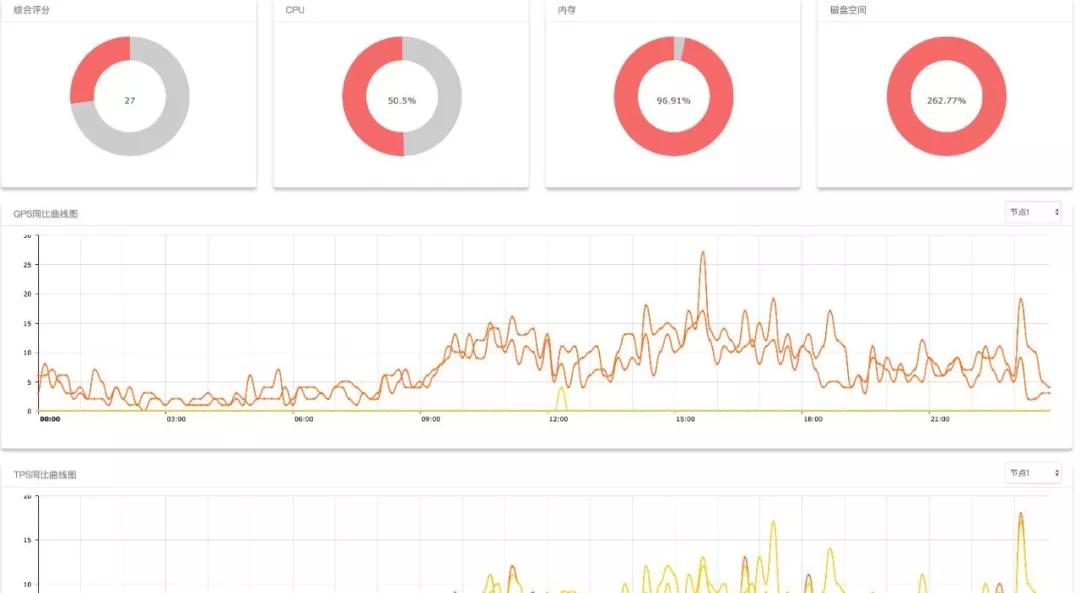
宝贝详情
②指标值预测分析
对于储存空间做了 7 日内低于 200G 的预测分析,由于多实例布署,因此必须对于现阶段宿主机上的实例开展现阶段数据信息尺寸、日志大小、日提高发展趋势的测算。
DBA 可以迅速精准定位必须转移扩充的连接点实例。完成方式便是用了 Prometheus 的 predict_linear 来完成的(实际使用方法可以参考官方网文本文档)。

储存空间预警信息
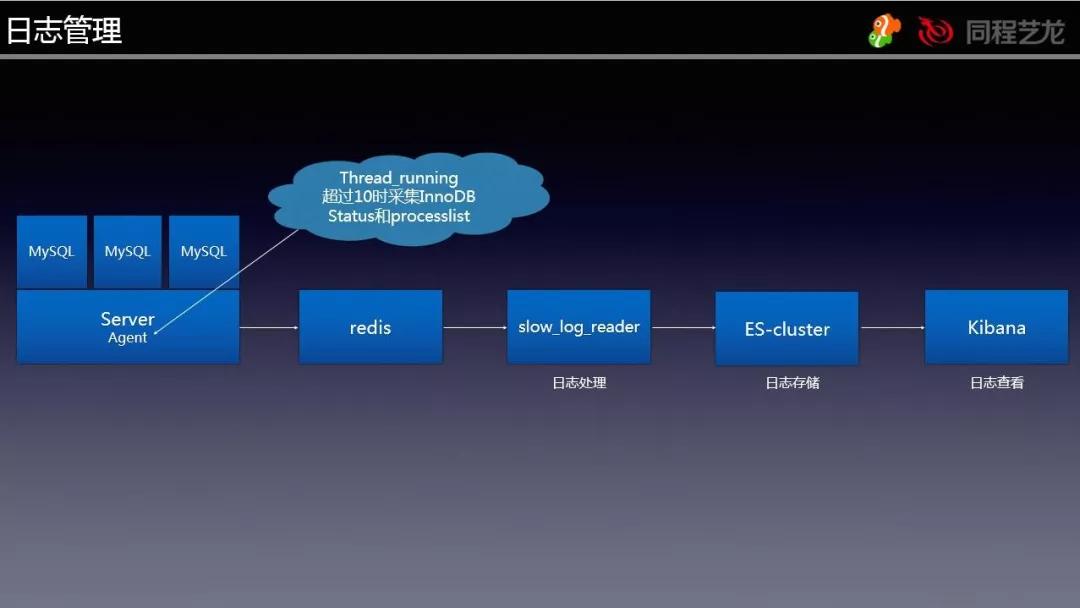
日志有关
①SlowLog
SlowLog 管理方法,我们都是根据一套体系来开展搜集、剖析的,由于要取得原生态日志,因此就沒有选用 pt-query-digest 的方法。
构架如下所示:
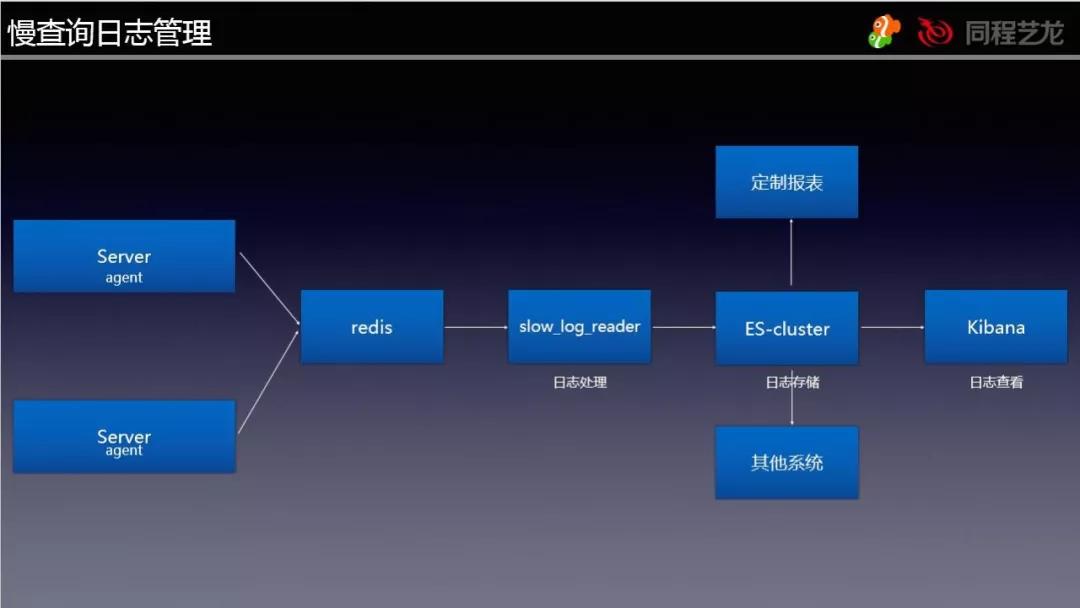
根据 Agent 搜集,随后将原有的日志恢复出厂设置之后以 LPUSH 方法载入 Redis(因为信息量并不算太大,因此就没有用 Kafka 或是 MQ),随后再由 slow_log_reader 这一程序流程根据 BLPOP 的方法读取,而且解决之后载入 ES。
这一流程主要是完成了 SQL 指纹识别获取、分块库库名重新写过为逻辑性库名的实际操作。
载入 ES 之后就可以用 Kibana 去查看数据信息。

对收到朝向开发设计的数据库查询一站式服务平台,业务流程开发设计的朋友可以查看自身有管理权限的数据库查询,与此同时大家也集成化了小米手机开源系统的 SOAR,可以用这一专用工具来查询 SQL 的改进提议。

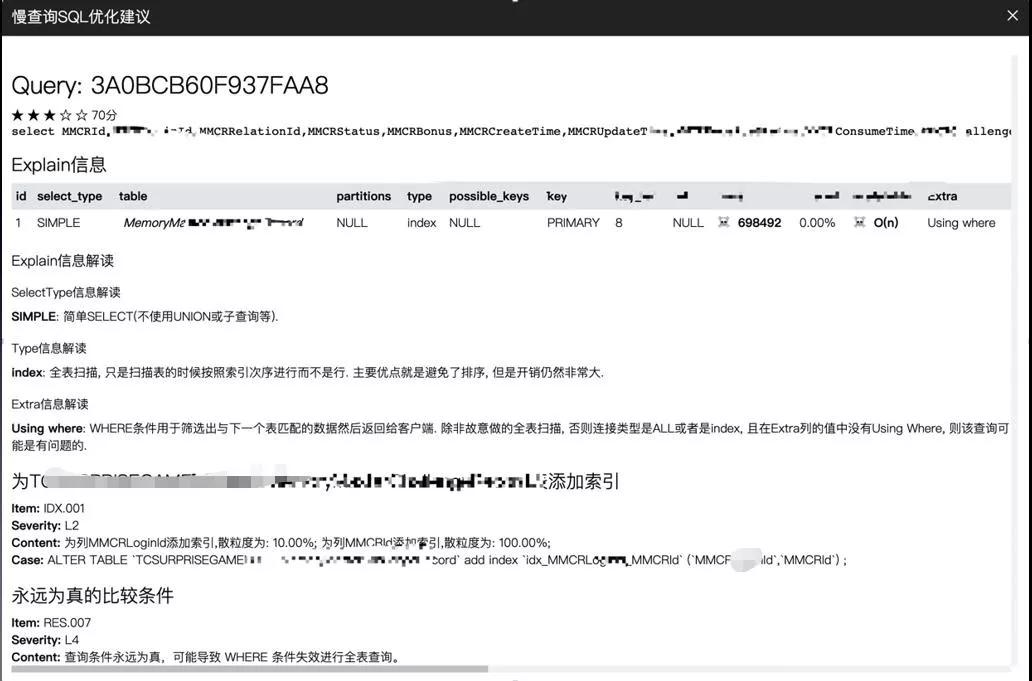
根据 ES 开展汇聚,可以给客户定阅慢查询的表格,有目的性的查询有关库的 TOP 慢 SQL 信息信息,有目的性的镜像文件提升。
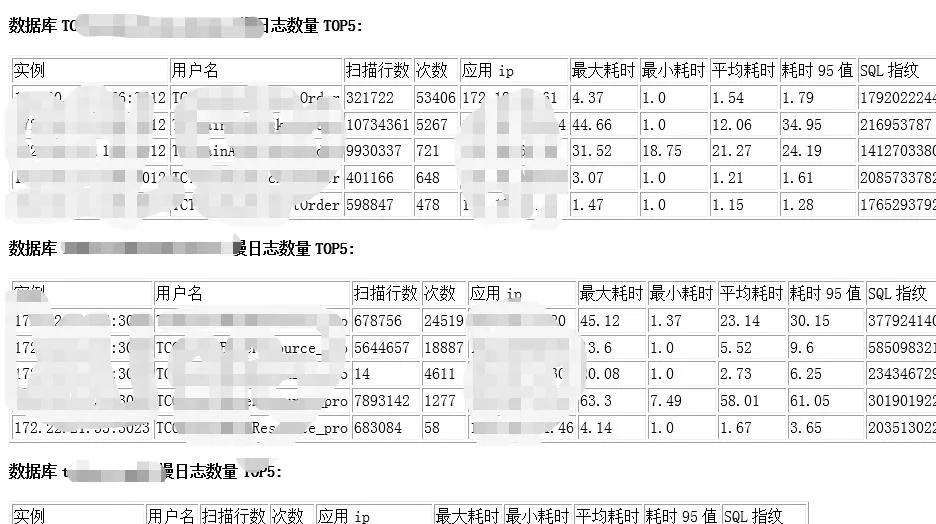
②Processlist,InnoDBStatus 数据采集
为了更好地能在常见故障回朔或是常见故障时查询当初的对话快照更新和 InnoDBStatus,我们在监控 Agent 中内嵌了这种作用,也是每 10 秒一次,差别是会分辨现阶段 ThreadRunning 是不是抵达阀值,假如抵达才会采集数据,不然不收集。
那样的设置既解决了没用日志过多的问题,又解决了特性出现异常时可以获得到情况信息。
下面的图是日志收集解决的逻辑性,在其中日志解决控制模块是和慢查询解决在一个程序流程中,对话快照更新的解决逻辑性和慢查询相近,这儿也不赘述了。
汇总
监控系统软件沒有肯定的谁好谁不太好,最重要的是合适自身的精英团队,可以合理安排最少的成本费解决困难。
大家从 2016 年刚开始应用 1.x 版本到实体的 2.x 版本,现阶段根据 Prometheus 的监控系统软件,承重了全部服务平台全部案例、宿主机、器皿的监控。
收集周期时间 10秒,Prometheus 1 分鐘内每秒钟均值摄入样本量 9-10W。
1 台物理机(不包括高可用性容灾資源)就可以承重现阶段的总流量,而且也有非常大的容积室内空间(CPU\Memory\Disk)。假如将来单机版没法支撑点的情形下,可以扩充成联邦政府群集方式。
此外这篇文章中提及的监控系统软件仅仅大家运维服务平台中的一个控制模块,并非一个单独的系统软件,从大家社会经验看来,最好可以融合到运维服务平台中去,完成技术栈收敛性和系统软件实用化、平台化,减少应用的错综复杂的。
最终说说在监控层面大家将来想要做的事儿,现阶段大家监控数据信息拥有,可是报警仅仅推送了标准的內容,实际的根因还必须 DBA 剖析监控信息。
大家方案在第一阶段完成报警指标值相关分析后,可以得出一个综合性好几个监控指标值得到的结果,协助 DBA 迅速精准定位;第二阶段可以更为剖析結果得出解决提议。
最后依靠全部监控管理体系,减少运维的复杂性,连通运维与业务流程开发设计立即的沟通交流堡垒,提高运维高效率和服务水平。
创作者:闫晓宇
介绍:同程艺龙数据库系统权威专家,具备很多年IT行业 DB 运维工作经验,游戏中、O2O 及电商行业从业过 DBA 运维工作中。2016 年添加同程艺龙,现阶段在精英团队承担数据库架构设计方案及提升、运维自动化技术、MySQL 监控服务体系、DB 私有云存储服务平台设计方案及开发设计工作中。
